# from twisted.internet import reactor, protocol# from pymodbus.client.async import ModbusClientProtocol## def print_result(result):# print("Result: %d" % result.bits[0])## def process(client):# result = client.write_coil(1, True)# result.addCallback(print_result)# reactor.callLater(1, reactor.stop)### defer = protocol.ClientCreator(reactor, ModbusClientProtocol).connectTCP("localhost", 502)# defer.addCallback(process) ###############3 # from twisted.internet import reactor# from pymodbus.client.async import ModbusClientFactory## def process():# factory = reactor.connectTCP("localhost", 502, ModbusClientFactory())# reactor.stop()## if __name__ == "__main__":# reactor.callLater(1, process)# reactor.run() ############### class unicode(): def unicode_test(value): import unicodedata name = unicodedata.name(value) value2 = unicodedata.lookup(name) print('value="%s", name="%s", value2="%s"' %(value, name, value2)) unicode.unicode_test('A') class writeFile(): poem = '''Beautiful is the 'thank you'Wrapped with gratitude, Offered to peace prone peopleWho offer what is real-themselvesTo nurse with love and humilitynapalm asphyxiated victims in our stained world''' fout = open('relativity.txt', 'wt') print(poem, file=fout, sep='', end='') fout.close() print(len(poem)) fin = open('relativity.txt', 'rt') poem = fin.read() fin.close() byteData = bytes(range(0, 256)) print(len(byteData)) with open('byteData.txt', 'wb') as fout: size = len(byteData) offset = 0 chunk = 50 while True: if offset > size: break fout.write(byteData[offset:offset+chunk]) offset += chunk print(offset) with open('byteData.txt', 'rb') as fout: bdata = fout.read() print(fout.tell()) print(fout.seek(25)) print(len(bdata)) import os print(os.SEEK_SET) import csv villains = [['Doctor', 'No'], ['Doctor', 'No'], ['Doctor', 'No'], ['Doctor', 'No'], ['Rosa', 'klebb']] with open('villains', 'wt') as fout: csvout = csv.writer(fout) csvout.writerows(villains) with open('villains', 'rt') as fin: cin = csv.reader(fin) newVillains = [row for row in cin] print(newVillains) with open('villains', 'rt') as fin: cin = csv.DictReader(fin, fieldnames=['first', 'second']) newVillains = [row for row in cin] print(newVillains) import shutil as st st.move('villains', 'copy_villains') path = os.path.abspath('villains') print(path) listdir = os.listdir('C:/python exercise/python_modbus/') print(listdir) import subprocess as sp date = sp.getoutput('date') print(date) import multiprocessing as mp import os def do_this(what): whoami(what) def whoami(what): print("Process %s says: %s" % (os.getpid(), what)) if __name__ == "__main__": whoami("I'm the main program") for n in range(4): p = mp.Process(target=do_this, args=("I'm function %s" % n)) p.start() writeFile()
1. 什麼是 Modbus 協定?
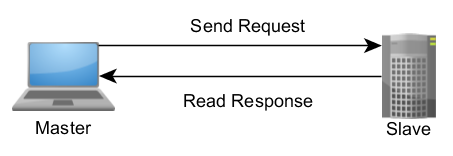
Modbus 是一種需求-回應協定,採用主從架構實作而成。 主從架構的通訊作業會成雙成對的出現,必須有個裝置啟動需求並等候回應,也就是說,這個啟動需求的裝置 (主要裝置) 會負責啟動每一次互動。 一般而言,主要裝置會是人機介面 (HMI) 或監控與資料擷取 (SCADA) 系統,附屬裝置則是感測器、程式化邏輯控制器 (PLC) 或程式化自動控制器 (PAC)。 這些需求和回應的內容、傳送訊息所經過的網路層,都是由此協定的不同層級所定義的。
Modbus 協定層級
初步實作的時候,Modbus 原本是以序列為基礎的單一協定,因此無法分成好幾層。 之後陸續引進不同的應用資料單位,目的在於改變序列所使用的封包格式,或是為了使用 TCP/IP 和使用者資料包通訊協定 (UDP) 網路。 這樣一來就會分割「核心協定」和「網路層」,前者定義了協定資料單元 (PDU),後者定義了應用資料單元 (ADU)。
2. 協定資料單元 (PDU)
PDU 和負責處理 PDU 的程式碼包含了 Modbus 應用協定規格的核心。 此規格定義了 PDU 的格式、協定所使用的不同資料概念、如何使用存取資料的函式代碼、每個函式代碼特定的實作方式與限制。
Modbus PDU 格式定義為函式代碼,接著是一組相關的資料集。 函式代碼會定義這筆資料的大小和內容,而且整個 PDU (函式代碼和資料) 的大小不得超過 253 位元。 每個函式代碼都有特定的行為,附屬裝置可以根據所需的應用行為靈活實作函式代碼的行為。 PDU 規格定義了資料存取與操作的核心概念;然而,附屬裝置可以該規格未明確定義的方式來處理資料。
Modbus 的資料存取方式和 Modbus 資料模式
一般來說,可透過 Modbus 存取的資料會存放在四種資料組間或位址範圍: Coil、離散輸入、保存暫存器、輸入暫存器。 就像大多數的規格一樣,名稱可能會因為產業或應用而有所不同。 舉例來說,保存暫存器也可能稱為輸出暫存器,Coil 則可能稱為數位或離散輸出。 這些資料組間定義了其中資料的類型和存取權限。 附屬裝置可直接存取此資料,同時這些資料則是存放於這些本端裝置內。 Modbus 可存取的資料通常是裝置主要記憶體的子資料集。 相反的,Modbus 主要裝置必須透過不同的函式代碼,才能提出這些資料的存取需求。 每個區塊的行為如表 1 所示。
| 記憶體區塊 | 資料類型 | 主機裝置存取 | 附屬裝置存取 |
| Coil | Boolean | 讀/寫 | 讀/寫 |
| 離散輸入 | Boolean | 僅讀取 | 讀/寫 |
| 保存暫存器 | 無正負號字詞 | 讀/寫 | 讀/寫 |
| 輸入暫存器 | 無正負號字詞 | 僅讀取 | 讀/寫 |
表 1. Modbus 資料模式區塊
這些區塊有助於限制或允許不同資料元素的存取權限,還能夠在應用層提供簡化的機制,以便存取不同的資料類型。
這些區塊通常都是概念性質的, 而且會在特定系統內以不同的記憶體位址存在,但也可能會重疊。 舉例來說,Coil 在記憶體內的位置可能和保存暫存器 1 代表字詞的第一個位元相同。 位址設定機制完全由附屬裝置定義,解讀每個記憶體區塊的方式也是裝置資料模型的關鍵之一。
資料模式的位址設定
此規格定義了每個區塊,位址空間最多可容納 65,536 (216) 個元素。 就 PDU 的定義而言,Modbus 定義了每個資料元素的位址,範圍從 0 開始到 65,535。 然而,每個資料元素會從 1 到 n 開始編號,n 的最大值是 65,536。 也就是說,Coil 1 位於 Coil 區塊的位址 0,保存暫存器 54 則是位於附屬裝置定義為保存暫存器的記憶體區塊中的位址 53。
規格可容許的完整範圍不一定要透過特定裝置才能實作。 舉例來說,裝置可選擇不要實作 Coil、離散輸入或輸入暫存器,而是僅使用編號 150 ~ 175 和 200 ~ 225 的暫存器。 這也是完全可以接受的做法,無效的存取意圖則是做為例外處理。
資料位址設定範圍
雖然此規格會把不同的資料類型定義為不同區塊內既有的類型,並且指派本端的位址範圍給每個類型,但卻不一定會是直覺式的位址設定機制,可能無法滿足建檔需求或有助於理解特定裝置中 Modbus 可存取的記憶體。 為了簡化記憶體區塊位置的討論,我們會介紹一個編號機制,可以在資料位址加上前置詞。
舉例來說,裝置手冊可能不會把某個項目稱為位址 13 的保存暫存器 14,而是以位址 4,014、40,014 或 400,014 來指稱某個資料項目。 就每個情況而言,第一個數字 4 代表了保存暫存器,其餘的數字則是代表位址。 4XXX、4XXXX 和 4XXXXX 取決於裝置所使用的位址空間。 如果全部 65,536 個暫存器都用到了,就應該會用到 4XXXXX 的編號方式,因為可允許的範圍是 400,001 到 465,536。
但如果只使用一部分的暫存器,常見的做法就是採用 4,001 到 4,999 的範圍。
就此位址設定機制而言,每個資料類型都會指派前置詞,如表 2 所示。
| 資料區塊 | 前置詞 |
| Coil | 0 |
| 離散輸入 | 1 |
| 輸入暫存器 | 3 |
| 保存暫存器 | 4 |
表 2. 資料範圍前置詞
Coil 的前置詞是 0。 也就是說,參考 4001 可能是指保存暫存器 1 或 Coil 4001。 因此,建議所有的全新實作採用 6 位元、0 開頭的位址設定機制,並且在說明文件中明確標示。 所以保存暫存器 1 會是 400,001,Coil 4001 則是 004,001。
資料位址起始值
特定應用所選擇的索引方式還會進一步讓記憶體位址與參考編號之間的差別變得更複雜。 如之前所述,保存暫存器 1 位於位址 0。 一般來說,參考編號的索引方式以 1 為主,也就是說,特定範圍的起始值是 1。 所以 400,001 直接代表保存暫存器 00001,位於位址 0。 有些實作方是的範圍起始值是 0,也就是說 400,000 代表了位址 0 的保存暫存器。 表 3 說明了此概念。
| 地址 | 暫存器編號 | 編號 (1 索引,標準方式) | 編號 (0 索引,替代方式) |
| 0 | 1 | 400001 | 400000 |
| 1 | 2 | 400002 | 400001 |
| 2 | 3 | 400003 | 400002 |
表 3. 暫存器索引設定機制
1 索引範圍相當常見,我們也強力建議此方式。 無論採用哪一種方式,都應該在說明文件中標示每個範圍的起始值。
大型資料類型
Modbus 標準提供過度簡化的資料模式,除了無正負號字詞和位元值之外,完全沒有其他的資料類型。 雖然就某些系統而言這兩種類型已經很夠用了,位元值可對應到螺線管和繼電器,字詞值則可對應到未經調整的 ADC 數值,卻無法滿足進階系統的需求。 因此,許多 Modbus 實作所包含的資料類型跨越了暫存器的界限。 NI LabVIEW 資料記錄與監控 (DSC) 模組和 KEPServerEX 都定義了一些參考類型。 舉例來說,存放在保存暫存器的字串會按照標準格式 (400,001),後面再加上小數點、長度和該字串的位元順序 (400,001.2H 代表兩個字元的字串,位於保存暫存器 1 內,其中的高位元組對應至字串的第一個字元)。 因為每個需求的大小有限,所以必須這麼做,也因此 Modbus 主要裝置必須知道確切的字串界限,不必像 0 值那樣搜尋長度或定義符號。
位元存取
除了可以存取跨暫存器界限的資料之外,有些 Modbus 主要裝置還可支援某個暫存器內個別位元的參考功能。 這麼做的好處是,可在相同的記憶體範圍內結合不同類型的資料,不必把二進制資料分割至 Coil 範圍和離散輸入範圍。 取決於實作方式,通常會使用一個小數點和位元索引或數字來表示。 也就是說,第一個暫存器的第一個位元可能是 400,001.00 或 400,001.01。 我們強力建議說明文件標示所使用的索引機制。
資料 Endianness
只要在兩個暫存器之間分割資料,就可以透過 Modbus 輕鬆傳輸多暫存器資料,例如單精度浮點數值。 因為標準並未定義這種狀況,所以這種分割方式的 Endianness (也就是位元順序) 也沒有定義方式。 雖然每個無正負號的字詞必須以網路 (big-endian) 的位元順序傳送出去才能符合標準規定,很多裝置都會針對多位元資料採用相反的位元順序。 圖 2 是不太常見卻有效的反向範例。

圖 2. 多字詞資料的位元順序交換
主要裝置會負責了解附屬裝置把資訊儲存至記憶體、有效解碼的方式。 我們強力建議說明文件明確標示系統所使用的字詞順序。 如果必須確保實作彈性,也可把 Endianness 加入系統的設定選項,搭配基本的編碼與解碼功能。
字串
Modbus 暫存器可以輕鬆儲存字串。 為了簡單起見,有些實作方式會規定字串長度必須是 2 的倍數,多餘的空間則以 0 值填入。 位元順序也會影響字串互動。 字串格式可能會也可能不會包含做為最後數值的 0 值。 有些裝置儲存資料的方式說明了這種變化,如圖 3 所示。

圖 3. Modbus 字串中反向的位元順序
了解函式代碼
資料模式會因為裝置而有所不同,甚至差異甚大,相反的,標準皆明確定義了函式代碼和其資料。 每個函式都具有特定的樣式。 首先,附屬裝置會檢驗函式產生器、資料位址和資料範圍等輸入內容。 接著會執行所需的行動,並且把合適的回應傳送至程式碼。 如果此程序有任何步驟出錯,就會把例外回傳至提出需求的裝置。 負責這些需求的資料運輸工具就是 PDU。
Modbus PDU
PDU 包含一個位元的函式代碼,後面最多可加上 252 個位元的函式專屬資料。

圖 4. Modbus PDU
函式代碼是第一個要檢驗的項目。 如果接收需求的裝置無法辨識函式代碼,就會以例外來回應此需求。 如果要接受這個函式代碼,附屬裝置就會根據函式定義,開始分析這筆資料。
封包大小的限制是 253 位元,所以裝置會受限於可傳輸的資料量。 最常見的函式代碼可以從附屬裝置的資料模式傳輸 240 到 250 位元的實際資料,視代碼而定。
附屬函式執行
根據資料模型的定義,不同的函式會存取不同的概念資料區塊。 常見的實作方式就是讓程式碼存取靜態記憶體位置,但也可以提供其他行為。 舉例來說,函式代碼 1 (讀取 Coil) 和 3 (讀取保存暫存器) 或許可以存取記憶體內相同的實體位置。 相反的,函式代碼 3 (讀取保存暫存器) 和 16 (寫入保存暫存器) 可能會存取完全不同的記憶體位置。 因此,最好把每個函式代碼的執行當作附屬裝置資料模式定義的一部分。
無論實際執行什麼行為,所有的附屬裝置都應該要遵從每個需求的簡易狀態圖。 圖 5 顯示了代碼 1 讀取 Coil 的相關範例。

圖 5. Modbus 協定規格
的讀取 Coil 狀態圖
每個附屬裝置都要檢驗函式代碼、輸入數量、起始位址、整體範圍,還有實際執行讀取、由附屬裝置定義的函式。
雖然靜態位址範圍如上方狀態圖所示,但是實際系統的需求可能會造成這些範圍不同於所定義的數值。 就某些情況而言,附屬裝置無法傳輸協定所定義的最大位元數量。 也就是說,無法讓主要裝置送出 0x07D0 輸入需求,只能回傳 0x0400 回應。 一樣的道理,附屬裝置資料模式或許把可接受的 Coil 數值範圍定義為位址 0 到 500。 如果主要裝置的需求是從位址 0 開始的 125,那就沒問題;但如果主要裝置從位址 400 開始提出相同的需求,最後的 Coil 就會落在位址 525,超過裝置所定義的範圍,所以會造成狀態圖所定義的例外 02。
標準函式代碼
規格會標示每個標準函式代碼的定義。 就算是最常見的函式代碼,主要裝置啟動的函式和附屬裝置可處理的部分之間難免有誤差。 為了解決此問題,早期的 Modbus TCP 規格版本定義了三種符合等級。 官方的 Modbus Conformance Test Specification 並未說明這些等級,反而根據每個函式提供了符合基準;不過還算是方便好懂。 我們強力建議所有的說明文件都按照測試規格,並且根據可支援的程式碼來定義符合內容,而不是根據舊有的分類。
等級 0 代碼
等級 0 代碼通常被視為實用 Modbus 裝置的極限最小值,能夠讓主要裝置讀寫資料模式。
| 代碼 | 說明 |
| 3 | 讀取多個暫存器 |
| 16 | 寫入多個暫存器 |
表 4. 符合等級 0 代碼
等級 1 代碼
等級 1 函式代碼包含了存取資料模式所有類型所需的其他代碼。 原始定義的列表包含了函式代碼 7 (讀取例外)。 然而,目前的規格把此代碼定義為僅限序列的代碼。
| 代碼 | 說明 |
| 1 | 讀取 Coil |
| 2 | 讀取離散輸入 |
| 4 | 讀取輸入暫存器 |
| 5 | 寫入單一 Coil |
| 6 | 讀取單一暫存器 |
| 7 | 讀取例外狀態 (僅限序列) |
表 5. 符合等級 1 代碼
等級 2 代碼
等級 2 函式代碼是更專門的代碼,實作機率也較低。 舉例來說,讀/寫多個暫存器可能有助於減少需求-回應週期的整體數量,但是仍然可以透過等級 0 代碼來實作此行為。
| 代碼 | 說明 |
| 15 | 寫入多個 Coil |
| 20 | 讀取檔案紀錄 |
| 21 | 寫入檔案紀錄 |
| 22 | 遮罩寫入暫存器 |
| 23 | 讀/寫多個暫存器 |
| 24 | 讀取 FIFO |
表 6. 符合等級 2 代碼
Modbus 封裝介面
Modbus 封裝介面 (Modbus Encapsulated Interface,MEI) 代碼,也就是函式 43,可以把其他資料封裝至一個 Modbus 封包裡面。 目前有兩個可用的 MEI 編號:13 (CANopen) 和 14 (Device Identification)。
函式 43/14 (Device Identification) 很實用的原因在於可傳輸高達 256 獨特物件。 其中有些物件經過事先定義與保留,例如廠商名稱與產品代碼,不過應用程式可定義其他的物件,做為一般的資料集傳送出去。
這種代碼的實作機率也不高。
例外
附屬裝置會使用例外來表示一些不好的狀況,像是組成不良的需求或錯誤輸入等等。 然而,例外狀況也可能是針對無效需求而產生的應用等級回應。 附屬裝置不會回應例外所發出的需求。 附屬裝置反而會忽略不完整或損毀的需求,開始等候新的訊息進來。
例外會以定義過的封包格式提報出去。 首先,函式代碼會送回提出需求、等於原始函式代碼的主要裝置,除了最重要的位元集之外。 其實就等於原始函式代碼的數值再加上 0x80。 例外回應會取代特定函式回應相關的正常資料,並且納入一個例外代碼。
標準內四個最常見的例外代碼是 01、02、03 和 04。 表 7 列出了這些代碼和每個函式的標準含義。
| 例外代碼 | 代表含義 |
| 01 | 不支援所收到的函式代碼。 根據原始的函式代碼,回傳的數值必須扣掉 0x80。 |
| 02 | 該需求試圖存取無效的位址。 根據標準內容,這是因為起始位址和所需的數值編號超過了 216。 然而,有些裝置可能會在資料模式中限制這個位址空間。 |
| 03 | 該需求包含錯誤資料。 有時候這表示參數比對出錯,例如所傳送的暫存器數量不符合 Byte Count 欄位。 比較常見的情況是,主要裝置需要的資料會多於附屬裝置或協定允許的資料。 舉例來說,主要裝置一次可能只會讀取 125 個保存暫存器,資源有限的裝置可允許的暫存器或許沒有這麼多。 |
| 04 | 嘗試處理需求的時候出現了無法復原的錯誤。 這是一個 Catchall 例外代碼,代表雖然需求有效,但是附屬裝置無法執行此需求。 |
表 7. 常見的 Modbus 例外代碼
每個函式代碼的狀態圖至少都應該包含例外代碼 01,通常也會有例外代碼 04、02、03,其他定義過的例外代碼則是不一定。
3. 應用資料單元 (ADU)
除了 Modbus 協定的 PDU 核心所定義的功能之外,也可使用多個網路協定。 最常見的協定就是序列和 TCP/IP,但也可使用 UDP 等其他協定。 為了透過這些層級傳輸 Modbus 必須的資料,Modbus 會納入一組專門為了每個網路協定而修改的 ADU 變化版本。
常見功能
Modbus 需要某些功能,才能夠提供穩定的通訊效能。 Unit ID 或 Address 會用於每個 ADU 格式,以便提供路由資訊給應用層。 每個 ADU 都具有完整的 PDU,其中包含了函式代碼和特定需求的相關資料。 為了保持穩定,每個訊息都會包含錯誤檢查資訊。 最後,所有的 ADU 都會提供一個機制,可判斷需求架構的開始與結尾,而且會以不同的方式加以實作。
標準格式
這三種標準的 ADU 格式分別是 TCP、遠端終程單元 (RTU)、ASCII。 RTU 和 ASCII ADU 通常會用於序列行,TCP 則是用於現代的 TCP/IP 或 UDP/IP 網路。
TCP/IP
TCP ADU 包含了 Modbus Application Protocol (MBAP) Header,透過 Modbus PDU 連接起來。 MBAP 是一種通用的標頭,仰賴穩定的網路層。 圖 6 顯示了這個 ADU 的格式,包含標頭在內。

圖 6. TCP/IP ADU
標頭的資料欄位說明了其用途。 首先,其中包含了傳輸識別碼。 如果網路上有多項需求同時懸宕,就會非常實用。 也就是說,主要裝置可以傳送需求 1、2、3。 之後附屬裝置就會以 2、1、3 的順序加以回應,然後主要裝置就可以把需求準確比對至回應和分割資料。 就乙太網路而言非常實用。
協定識別碼通常是 0,不過可用來放大協定的行為。 協定會使用長度欄位來表示剩餘封包的長度。 此元素的位置也證明了標頭格式必須仰賴穩定的網路層。 因為 TCP 封包具有內建的錯誤檢查資訊,可確保資料的相關性與傳輸,所以封包長度可能位於標頭的任何位置。 如果是內部比較不穩定的網路,像是序列網路,封包可能會遺失,所以就算應用程式所讀取的資料串流包含有效的傳輸與協定資訊,損毀的長度資訊也會造成標頭無效。 TCP 可針對此狀況提供合理的保護措施。
TCP/IP 裝置通常不會使用 Unit ID。 然而,因為 Modbus 是相當常見的協定,已開發出許多閘道,所以會把 Modbus 協定轉換成另一個協定。 就原先設定的用途而言,序列閘道的 Modbus TCP/IP 可以在全新 TCP/IP 網路和較舊序列網路之間建立連線。 在此環境下,Unit ID 會用來判斷 PDU 實際目標的附屬裝置位址。
最後,ADU 還包含一個 PDU。 就標準協定而言,這個 PDU 的長度仍然限於 253 個位元。
RTU
如圖 7 所示,RTU ADU 看起來比較簡單。

圖 7. RTU ADU
不同於較為複雜的 TCP/IP ADU,這個 ADU 除了核心 PDU 之外還包含了兩項資訊。 首先是一個位址,用來定義 PDU 目標的附屬裝置。 就大部分的網路而言,位址 0 代表廣播位址。 也就是說,主要裝置可能會把輸出指令傳送至位址 0,所有的附屬裝置都會處理此需求,但沒有一個會加以回應。 除了此位址之外,還有一個 CRC 會用來確保資料的完整度。
然而,真實情況卻沒有這麼簡單。 包圍此封包的是一組靜止時間,也就是說這段期間內匯流排不會有任何通訊。 如果鮑率是 9,600 的話,該比例大約是 4 ms。 標準所定義的最小靜止時間是 2 ms 以內,無論鮑率為何。
首先,因為裝置必須等候閒置時間結束,才能接著處理封包,所以會造成效能缺口。 更危險的是引進不同序列傳輸專用的技術,這會帶來比採用標準時更高的鮑率。 使用 USB 轉序列轉換線時,舉例來說,就無法控制封包化和資料傳輸作業。 測試結果顯示,使用 USB 轉序列接線搭配 NI-VISA 驅動程式會造成大規模的資料串流缺口,這些缺口就是靜止期間,會讓符合規格的程式碼相信訊息是完整的。 因為訊息不完整的關係,通常會造成 CRC 無效,而且裝置會把 ADU 解讀為已損毀。
除了傳輸問題之外,現代的驅動程式技術還會大量抽象化序列通訊作業,而且通常需要應用程式碼提供輪詢機制。 舉例來說,.NET Framework 4.5 SerialPort Class 和 NI-VISA 驅動程式都沒有可偵測序列通道上靜止時間的機制,只能輪詢連接埠上的位元。 這樣會造成效能漸趨低落 (如果輪詢速度太慢) 或高度使用 CPU (如果輪詢速度太快)。
有個常見的做法可以解決這些問題,就是打破 Modbus PDU 和網路層之間的抽象層。 也就是說,序列程式碼會詢答 Modbus PDU 封包以決定函式代碼。 這樣一來即可探索剩餘封包的長度和封包內的其他資料,並且用來判斷封包結尾。 有了這項資訊,就可以使用更長的暫停時間,藉此容納傳輸缺口,而且應用層級的輪詢也會更慢發生。 建議針對新的開發作業採用此機制。 不採用此機制的程式碼可能會遇到比預期內更大量的「損毀」封包。
ASCII
如圖 8 所示,ASCII ADU 比 RTU 還複雜,卻能夠避免許多 RTU 封包的問題, 不過還是有一些缺點。

圖 8. ASCII ADU
ASCII ADU 可以解決決定封包大小的問題,並且針對每個封包提供完整定義且獨特的開始與結尾。 也就是說,每個封包開始都是 :,結尾都是歸位 (CR) 和換行 (LF)。 此外,NI-VISA 和 .NET Framework SerialPort Class 等序列 API 都可以輕鬆讀取緩衝區的資料,直到收到特定字元為止,例如 CR/LF。 這些特色有助於在現代的應用程式碼中,輕鬆且有效處理序列通道的資料串流。
ASCII ADU 的缺點在於所有資料都會做為透過 ASCII 編碼而成的十六進位字元傳輸出去。 也就是說,不會針對函式代碼 3 傳送單一位元,而是傳送 ASCII 字元 0 和 3,或是 0x30/0x33。 這樣一來,此協定便有利於人工閱讀,但也代表必須透過序列網路傳輸兩倍的資料,而且傳送與接收應用程式必須能夠分割 ASCII 數值。
擴充 Modbus
Modbus 算是相對簡單且開放的標準,也可針對特定的應用需求加以修改。 HMI 和 PLC/PAC 之間的通訊作業經常有此修改需求,因為單一組織或許能夠同時控制此協定的兩個末端。 舉例來說,感測器的開發人員比較有可能遵守書面標準,因為他們通常只能控制附屬裝置的實作方式,並且需要互通效能。
一般來說,我們不建議修改協定。 此段落僅是提供別人曾經用來調整協定行為的機制。
4. 新的函式代碼
有些函式代碼經過定義,不過Modbus 標準也可讓使用者自行開發額外的函式代碼。 尤其是函式代碼 1 到 64、73 到 99、111 到 127 都是特別保留的公用代碼,可確保獨特性。 剩下的代碼包含 65 到 72 和 100 到 110,都可供使用者自行定義。 有了這些可供定義的代碼,即可使用各種資料架構。 資料甚至可以超過 Modbus PDU 所限制的標準 253 位元,但是必須檢驗整個應用,確保 PDU 超過標準限制時其他層級能夠正常運作。 127 以上的函式代碼則是保留用於例外回應。
5. 網路層
除了序列和 TCP 之外,Modbus 可以在多種網路層上運作。 可能的實作方式之一就是 UDP,因為很適合 Modbus 通訊風格。 Modbus 的核心就是一種訊息架構的協定,因為 UDP 能夠傳送完整定義的資訊封包,不需要額外的應用層級資訊,例如起始字元或長度,所以能更輕鬆實作 Modbus。 Modbus PDU 封包不需要額外的 ADU,也不會重複使用現有的 ADU,只要使用標準的 UDP API 即可傳送出去,並且在另一端完整接收。 雖然 TCP 內建的確認系統對某些協定來說非常有幫助,Modbus 卻是在應用層執行確認功能。 然而,以這種方式使用 UDP 就會省掉 TCP ADU 內的傳輸識別碼欄位,這樣一來就不會同時出現多項懸宕的傳輸項目。 因此,主要裝置必須是同步化的主要裝置,或者 UDP 封包必須具有識別碼,才能夠幫助主要裝置整理需求與回應。 我們建議在 UDP 網路層上使用 TCP/IP ADU。
6. 修改 ADU
最後,針對應用內容可能會需要修改 ADU,或者使用現有 ADU 中未曾使用過的部分,例如 TCP。 舉例來說,TCP 定義了一個 16 位元的長度欄位、16 位元協定、8 位元 Unit ID。 最大的 Modbus PDU 只有 253 位元,所以長度欄位的高位元組只會是 0。 就 Modbus/TCP 而言,協定欄位和 Unit ID 只會是 0。 只要把協定欄位改成 0 以外的數字,使用兩個未曾使用過的位元 (Unit ID 和長度欄位的高位元組) 來傳送兩個額外 PDU 的長度,即可簡單擴充此協定,並且同時傳送三個封包 (如圖 9 所示)。

圖 9. 簡單修改 TCP ADU